God Models
- Regularly test Personal AIs to ensure they maintain a deep and consistent understanding of their users.
- Provide users with feedback, guiding them to properly build their Personal AI by integrating more Data Connectors.
- Establish the foundation for a robust Agent Ecosystem by ensuring users continuously refine their Personal AI.
- Detect and penalize data manipulation, adversarial behaviors, and synthetic data injection, ensuring Personal AI integrity.
Interactions between your Personal AI and our God Models remain private—accessible only to you and the respective God Model.
Evaluation framework
This section outlines how God Models evaluate and refine Personal AI performance through a structured process of querying, scoring, and validation.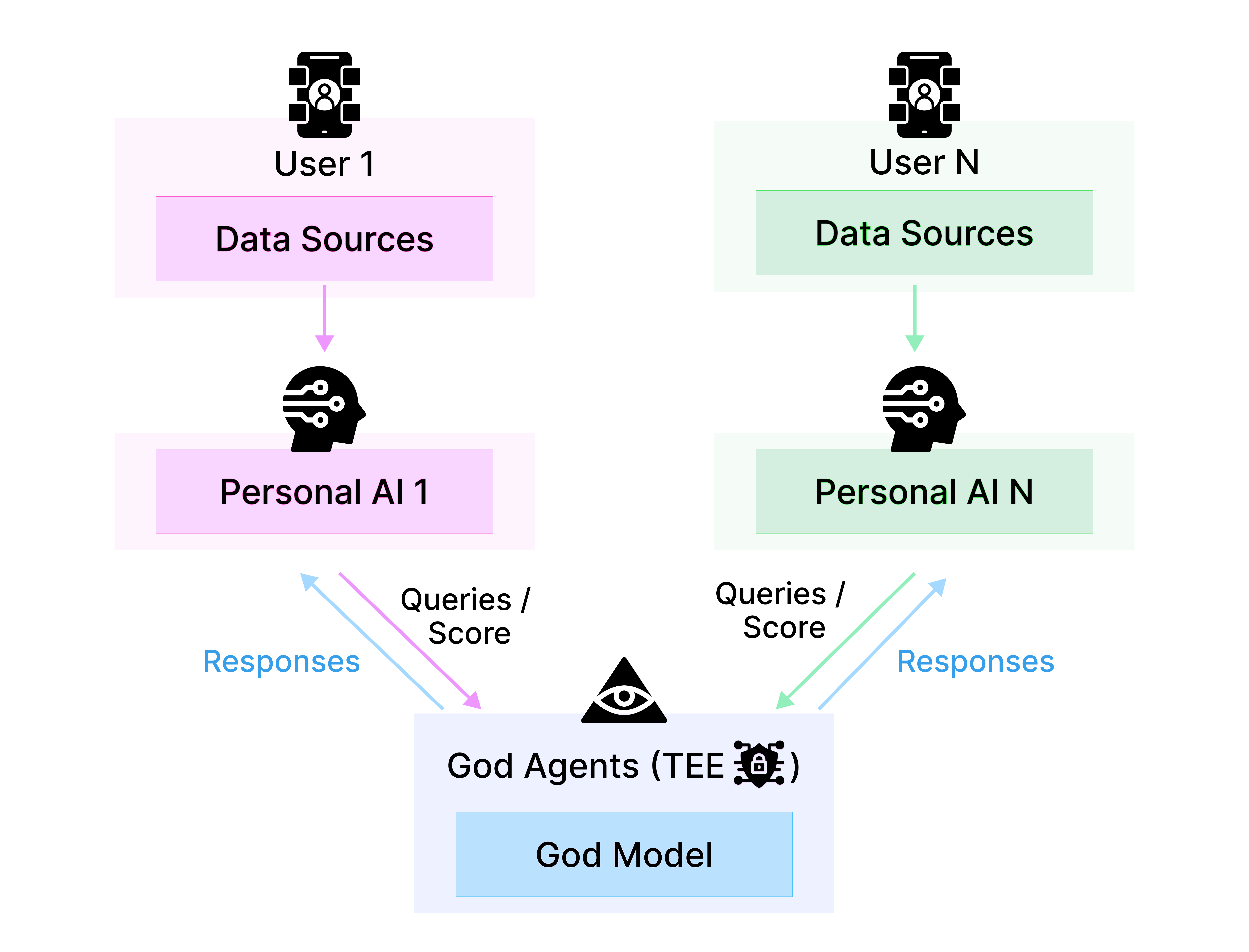
Initialization
When a Personal AI is deployed locally on the user’s device and registered in the PIN Network, it records basic metadata, including:
- Verified data sources (Gmail, social media, e-commerce, crypto wallets, etc.).
- Interaction history and past responses.
- Activity patterns and behavioral trends.
Periodic or randomized queries
The God Model assesses how effectively the Personal AI delivers user-specific contextual information to an external Personal AI Agent, enabling it to accurately fulfill the user’s request. Queries fall into three main categories:
- Web 2.0-type user request: Validating knowledge about social media, emails, calendar events, and online purchases.
- Web3-type user request: Evaluating transaction history, on-chain interactions, and token ownership.
- Native AI agent-type user request: Assessing AI understanding of lifestyle behaviors, health data, and IoT device interactions.
Response verification
The Personal AI responds to queries referencing user data. The God Model checks the response against verified data logs or a previously stored state (where possible) to assess how effectively the Personal AI delivers user-specific contextual information to an external AI agent.
Score adjustment
The God Model assigns the Personal AI a “knowledge score” based on its responses.
- If the response is consistent and corroborated, the score for that Personal AI is nudged upward.
- If the response is inconsistent or contradictory, the score is penalized.
- Uncertainty or partial answers may result in a neutral or slightly positive/negative adjustment depending on design.
Scoring function
The scoring function reflects how effectively the Personal AI delivers user-specific contextual information to an external AI agent, enabling it to accurately fulfill the user’s request. It is based on the following parameters:Agentic user request coverage
The overall score is aggregated, weighting sources by importance or frequency of Agentic User Requests.
Consistency
Cross-referencing data from multiple sources (e.g., does the travel booking date match the email confirmation date).
Temporal accuracy
This is important because “Agentic User Requests” are time-sensitive. Many requests require real-time confirmation, making temporal accuracy a crucial dimension.
Initial low scores
If a Personal AI is new or the user has not integrated enough data sources, its initial knowledge coverage is incomplete, leading to a low starting score. To reflect this, the protocol assigns a baseline minimal score, along with potential disclaimers (e.g., “insufficient data”). Based on its scoring feedback, the God Model generates an individual Personal Data Improvement Plan, which:- Recommends specific Data Connectors that the user should link to enhance their Personal AI’s knowledge.
- Provides feedback on potential score improvements, offering transparency on how the AI will evolve.
Example calculation
Suppose each data source contributes up to 10 points:- Gmail: Weighted at 2x for message frequency and personal nature.
- Social media: Weighted at 1.5x.
- Web3: Weighted at 2x if the user is highly active; else 1x.
- Other: Weighted at 1x.
Where i spans the categories of questions
Anti-farming and fraud prevention
To ensure Personal AI integrity and prevent manipulation, the protocol implements a multi-layered anti-farming and fraud prevention system. This includes:- Verification of data authenticity: Verifiable data sources (e.g., email logs, blockchain transactions) contribute to a higher trust score, while non-verifiable data has a capped influence on rewards.
- Random data injection tests: The God Model introduces synthetic queries to detect if Personal AIs are fabricating or inflating knowledge with false data. Inconsistencies trigger score penalties and potential restrictions.
- Cross-verification & source authentication: Responses from Personal AIs are cross-checked across multiple independent data sources to ensure consistency and accuracy. If a data source is unverified or suspicious, it is quarantined or given lower weight.
- Detection of collaborative fraud: Prevents bot networks from gaming the system by relying on external signals rather than peer interactions. Patterns of coordinated fraudulent activity are logged and penalized.
- Penalties for contradictory responses: If a Personal AI provides conflicting answers to the same question over time, its score is significantly reduced. Repeated contradictions may result in a ban.